大規模な言語モデルは、安定した拡散の瞬間を迎えています
2022 年 8 月に行われた Stable Diffusion 画像生成モデルの公開リリースは、重要な瞬間でした。私は当時、Stable Diffusion がいかに重要であるかを書きました。
人々は自分のハードウェアでテキストから画像を生成できるようになりました!
さらに重要なことに、開発者は何が起こっているのかをいじることができました。
結果として生じるイノベーションの爆発は、今日でも続いています。ごく最近、ControlNet は、その機能の点で、Midjourney や DALL-E よりも先に Stable Diffusion を飛躍させたようです。
8 月にさかのぼる Stable Diffusion の瞬間が、ジェネレーティブ AI へのまったく新しい関心の波を引き起こしたように感じます。その後、11 月末に ChatGPT がリリースされると、それはオーバードライブに追い込まれました。
ChatGPT 自体の背後にあるテクノロジーである大規模な言語モデルについて、その安定拡散の瞬間が今再び起こっています。
今朝、初めて自分のラップトップでGPT-3 クラスの言語モデルを実行しました。
AIのものはすでに奇妙でした。ますますおかしくなりそうです。
ラマ
やや驚くべきことに、ChatGPT のようなツールを強化する GPT-3 のような言語モデルは、画像生成モデルよりもはるかに大きく、構築と運用に費用がかかります。
これらのモデルの中で最も優れたものは、ほとんどが OpenAI などの民間組織によって構築されたものであり、厳密に管理されています。API や Web インターフェースを介してアクセスできますが、誰もが自分のマシンで実行できるようにはリリースされていません。
これらのモデルもBIGです。GPT-3 モデルを入手できたとしても、コモディティ ハードウェアで実行することはできません。通常、これらには複数の A100 クラスの GPU が必要であり、それぞれの小売価格は 8,000 ドル以上です。
このテクノロジーは明らかに重要すぎて、少数の企業グループによって完全に制御されることはありません。
過去数年間に何十ものオープンな大規模言語モデルがリリースされましたが、次の点で私にとって最適なモデルはありませんでした。
- 自分のハードウェアで簡単に実行できます
- 実用に十分な大きさ – 理想的には GPT-3 と同等の機能
- いじり回せるほどのオープンソース
Facebook のLLaMA モデルとGeorgi Gerganov によるllama.cppの組み合わせのおかげで、これが昨日変わりました。
LLaMA 論文の要約は次のとおりです。
7B から 65B のパラメーターに及ぶ基本言語モデルのコレクションである LLaMA を紹介します。何兆ものトークンでモデルをトレーニングし、独自のアクセスできないデータセットに頼ることなく、公開されているデータセットのみを使用して最先端のモデルをトレーニングできることを示しています。特に、LLaMA-13B はほとんどのベンチマークで GPT-3 (175B) を上回り、LLaMA-65B は最高のモデルである Chinchilla-70B および PaLM-540B と競合します。すべてのモデルを研究コミュニティに公開します。
LLaMA は完全に「オープン」ではないことに注意してください。モデルにアクセスするには、いくつかの厳密な条件に同意する必要があります。これは研究プレビューとして意図されており、商用目的で使用できるものではありません。
完全なサイバーパンクの動きで、リリースから数日以内に、誰かがこの PR をLLaMA リポジトリに送信し、モデル ファイルの非公式の BitTorrent ダウンロード リンクにリンクしました!
だから彼らは今、野生にいます。合法的にそれらの上に商用製品を構築することはできないかもしれませんが、魔神はボトルから出ています. あなたが聞くことができる猛烈なタイピング音は、世界中の何千人ものハッカーが掘り下げ始め、自分のハードウェアで GPT-3 クラスのモデルを実行できるときの生活がどのようなものかを理解し始めていることです。
ラマ.cpp
個人のラップトップで実行するのが難しすぎる場合、LLaMA だけではあまり良くありません。
ゲオルギ・ゲルガノフを入力してください。
Georgi は、ブルガリアのソフィアを拠点とするオープン ソース開発者です (彼の GitHub プロファイルによると)。彼は以前、OpenAI の Whisper 自動音声認識モデルを C++ に移植したwhisper.cppをリリースしました。このプロジェクトにより、ウィスパーは幅広い新しいユースケースに適用できるようになりました。
彼は LLaMA でも同じことをしたばかりです。
Georgi のllama.cppプロジェクトの最初のリリースが昨日ありました。README から:
主な目標は、MacBook で 4 ビット量子化を使用してモデルを実行することです。
4 ビット量子化は、モデルのサイズを小さくして、性能の低いハードウェアでも実行できるようにする手法です。また、ディスク上のモデルのサイズも削減されます。7B モデルでは 4GB、13B モデルでは 8GB 弱になります。
それは完全に機能します!
私は今晩ラップトップで 7B LLaMA モデルを実行するためにそれを使用し、今朝、Facebook が GPT-3 と競合すると主張する 13B モデルにアップグレードしました。
以下は、私がそれをどのように行ったかについての詳細なメモです。必要な情報のほとんどは、README に既に記載されています。
私のラップトップが私にテキストを吐き出し始めたとき、私は世界が再び変化しようとしていると心から感じました.
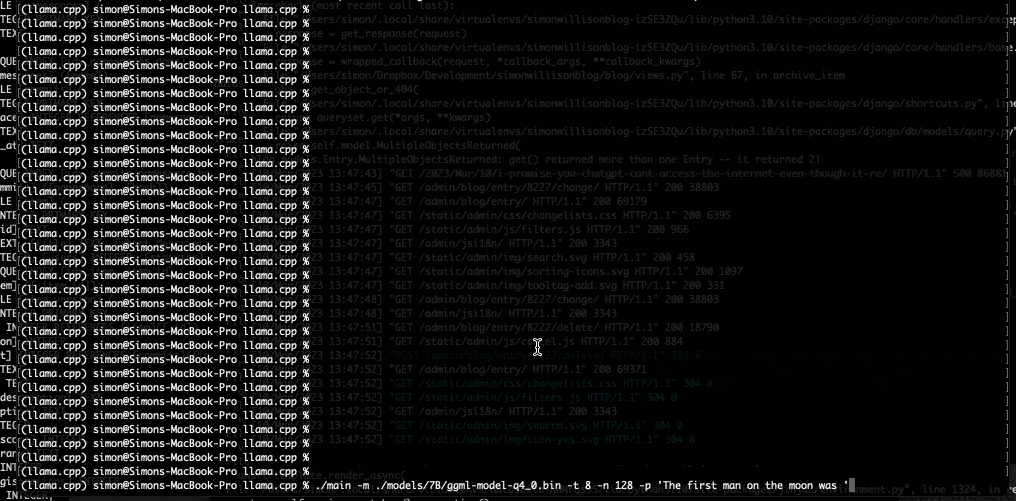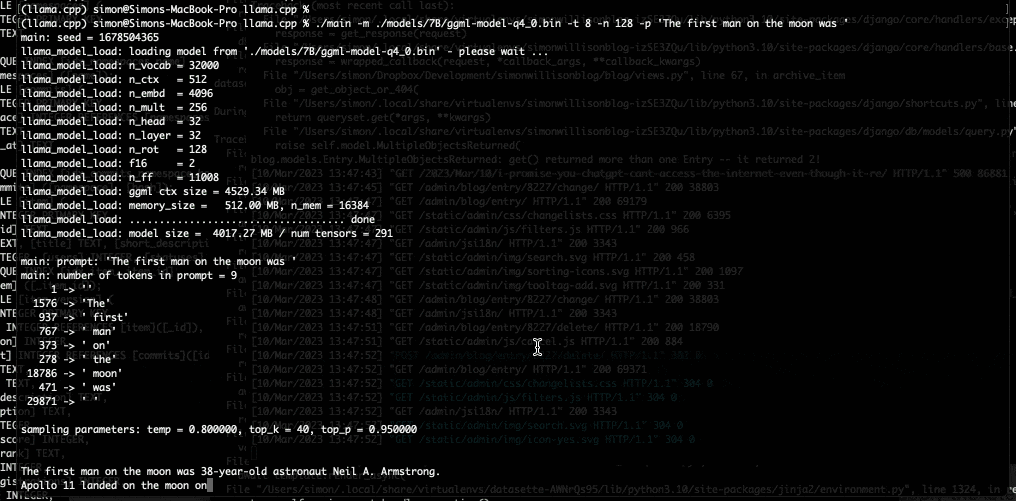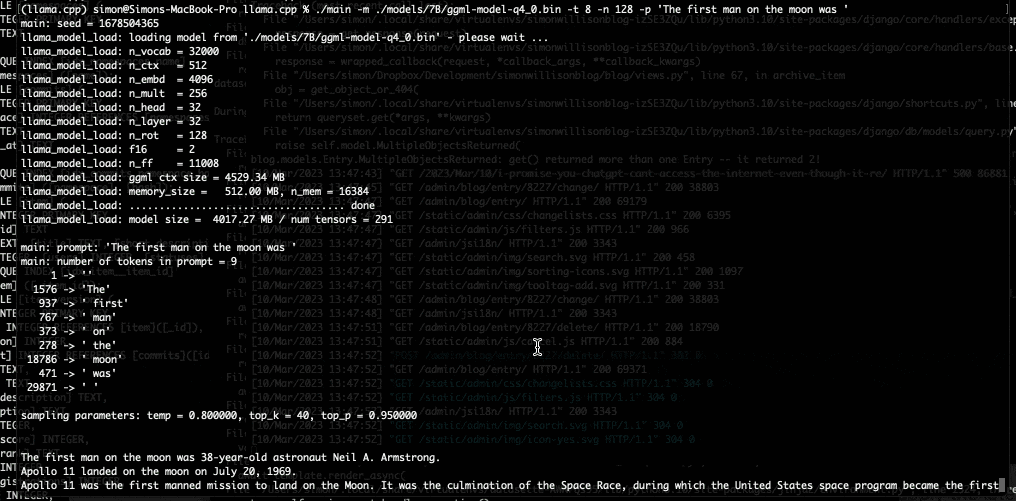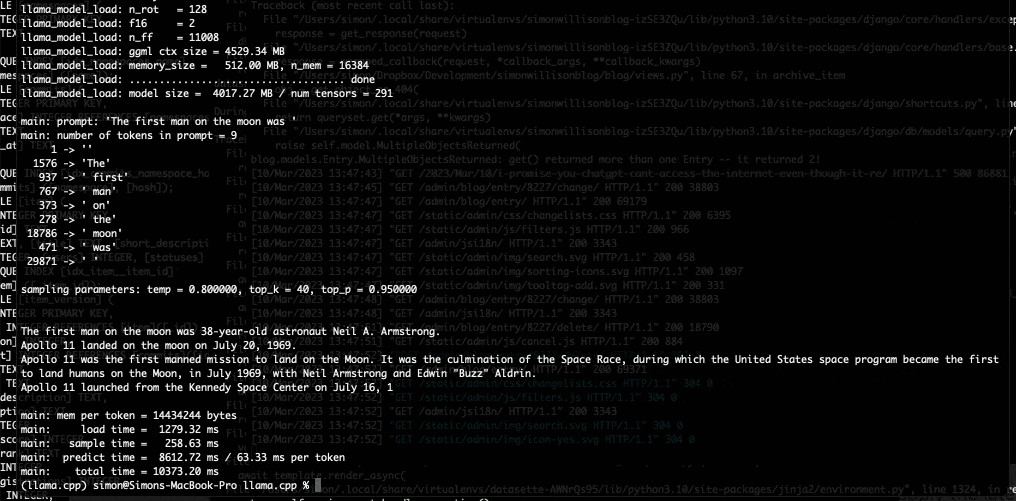
所有しているハードウェアで GPT-3 クラスのモデルを実行できるようになるまでには、あと数年かかると思っていました。私は間違っていました。その未来はすでにここにあります。
これは今までで最悪の出来事ですか?
ここでは、サイエンス フィクションのシナリオについては心配していません。私のラップトップで実行されている言語モデルは、解放されて世界を支配するAGI ではありません。
しかし、このテクノロジーが害を及ぼすために使用される非常に現実的な方法がたくさんあります。少しだけ:
- スパムの生成
- 自動ロマンス詐欺
- トローリングとヘイトスピーチ
- フェイクニュースと偽情報
- 自動化された過激化(私はこれについて非常に心配しています)
言うまでもなく、このテクノロジーは事実情報をオウム返しするのと同じくらい簡単に物事をでっち上げ、違いを見分ける方法を提供しません。
この瞬間以前は、OpenAI のような企業が、人々がそれらのモデルとどのように相互作用するかを制御する能力が限られているという点で、薄い防御層が存在していました。
これらを独自のハードウェアで実行できるようになったので、それらのコントロールさえなくなりました。
これをどのように使用しますか?
社会に与える影響は大きいと思います。私の優先事項は、その影響をポジティブな方向に向かわせることです。
ここには何も良いものはなく、すべてのジェネレーティブ AI は積極的に有害であるか、時間の無駄であると考える皮肉な罠に陥りがちです。
私は個人的に、さまざまな目的でジェネレーティブ AI ツールを日常的に使用しています。彼らは物質的な生産性を向上させてくれましたが、もっと重要なことは、私が引き受けるプロジェクトに関して私の野心を広げてくれたことです。
ちょうど先週、新しいプロジェクトを1 時間以内に出荷するのに十分な AppleScript を学習するために、ChatGPT を使用しました!
私は、このテクノロジーの真にポジティブな応用を探求し、共有し続けるつもりです。発明されていないわけではないので、私たちの優先事項は、それを使用するための最も建設的な方法を考え出すことだと思います.
次に探すもの
Facebook がライセンス条件を緩和しないと仮定すると、LLaMA は、人々が今後使用する新しい基盤モデルというよりも、消費者向けハードウェアでローカル言語モデルが実現可能であるという概念実証になる可能性があります。
人々が自分のデバイスで ChatGPT のような機能を利用できるようにする最初の完全にオープンな言語モデルをリリースする競争が続いています。
Stable Diffusion の支持者であるEmad Mostaqueの言葉を引用します。
フルオープン版あったらいいな
もう起きてる…
私はこの記事を 2023 年 3 月 11 日土曜日に公開しました。日曜日に、Artem Andreenko が 4GB の RAM を搭載した RaspberryPi で実行しました。
そして月曜日に、Anish Thite が Pixel 6 スマートフォンでそれを動作させました (26 秒/トークン):
その後、スタンフォード大学の研究所がアルパカをリリースしました。これは、モデルの命令を微調整したバージョンです。これについては、フォローアップの記事、Stanford Alpaca、およびデバイス上での大規模な言語モデル開発の加速で詳しく書きました。
私の仕事に従ってください
ブログに書いたものはすべてAtom フィードに送られ、非常にアクティブな Mastodon アカウントと、書いた新しいものへのリンクを投稿し続けるTwitter アカウント ( @simonw )があります。
また、 simonw.substack.comでニュースレターを開始しています。毎週ブログからすべてを発信する予定ですので、メールで最新情報を入手したい場合は、そこから購読してください。
私が書いた他のもの
私のジェネレーティブ AI タグにはすべてが含まれていますが、過去 1 年間の関連するハイライトをいくつか紹介します。
- GPT-3 によって作成されたデータセット チュートリアル — 2022 年 5 月 31 日
- GPT-3 言語モデルの使用方法— 2022 年 6 月 5 日
- テキストから画像を生成する DALL-E の第一印象— 2022 年 6 月 23 日
- GPT-3 を使用してコードの仕組みを説明する— 2022 年 7 月 9 日
- 安定拡散は本当に大きな問題です— 2022 年 8 月 29 日
- Stable Diffusion の背後にあるトレーニング データの探索— 2022 年 9 月 5 日
- GPT-3 に対する迅速なインジェクション攻撃 — 2022 年 9 月 12 日
- Whisper と GitHub の問題/アクションを使用してオンライン ビデオに対してキャプション抽出を実行するツール – 2022 年 9 月 30 日
- AI の呪文詠唱の比喩は有害ですか、それとも役に立ちますか? —2022 年 10 月 5 日
- 新しい AI ゲーム: 犯罪のアイデアをください— 2022 年 12 月 4 日
- AI 支援学習: ChatGPT、Copilot、Advent of Code を使用して Rust を学習— 2022 年 12 月 5 日
- GPT3、埋め込み、データセットを使用してドキュメントに対して Q&A を実装する方法— 2023 年 1 月 13 日
- ビング: 「あなたが先に私に危害を加えない限り、私はあなたに危害を加えません」 —2023 年 2 月 15 日
- テレビ生放送でBingについて語り、言語モデルの解説をしてみました!—2023年2月19日
- 迅速なエンジニアリングの擁護— 2023 年 2 月 21 日
- Bing の AI 支援検索に関する考えと印象— 2023 年 2 月 24 日
- ウィークノート: NICAR、および KQED フォーラムへの出演— 2023 年 3 月 7 日
- ChatGPT は、実際にはアクセスできるように見えますが、インターネットにアクセスできません— 2023 年 3 月 10 日